

How To Teach a Robot to Speak
How can a computer that only understands 1s and 0s grasp the nuances of language?

This newsletter is my attempt to capture and share some of what I'm learning as I dedicate more time to understanding AI, technology, and science. If you know someone nerdy enough to enjoy it, please forward it along.
Adventures with Language
What is it about language?
Sure, it’s amazing when a computer can do image detection or analyze data to find patterns.
But nothing quite boggles the mind like AI that understands and creates language. It feels so human, so connected with real thought and intelligence. There’s something spooky about it being generated by an algorithm.
I’ve been spending a lot of time building models that can classify text, extract ideas, summarize concepts, and even generate written output. It can start to feel like magic. So I wanted to step back and understand more deeply how exactly it’s possible for an AI model to capture something as shapeless and nuanced as language.
To explore that, I started with the very simplest example: a script where you can input a block of text and it’ll return the sentence from the block that best summarizes the point.
Here’s a link to a notebook where you can test it out.
Word2Vec
How did it do that? I mean, it’s not that impressive, but how is a computer that only understands numbers able to grasp enough of the meaning of a text to make a judgment call like that?
The answer is one of the most mindblowing things I’ve learned about in AI: word vectors.
Imagine you spoke a language that only had four words: king, queen, prince, and princess. Rather than using letters like ‘k’, ‘i’, ‘n’, ‘g’ to express these words, you might be able to represent the ideas better by plotting them on a graph, where the x-axis represents gender and the y-axis represents age:
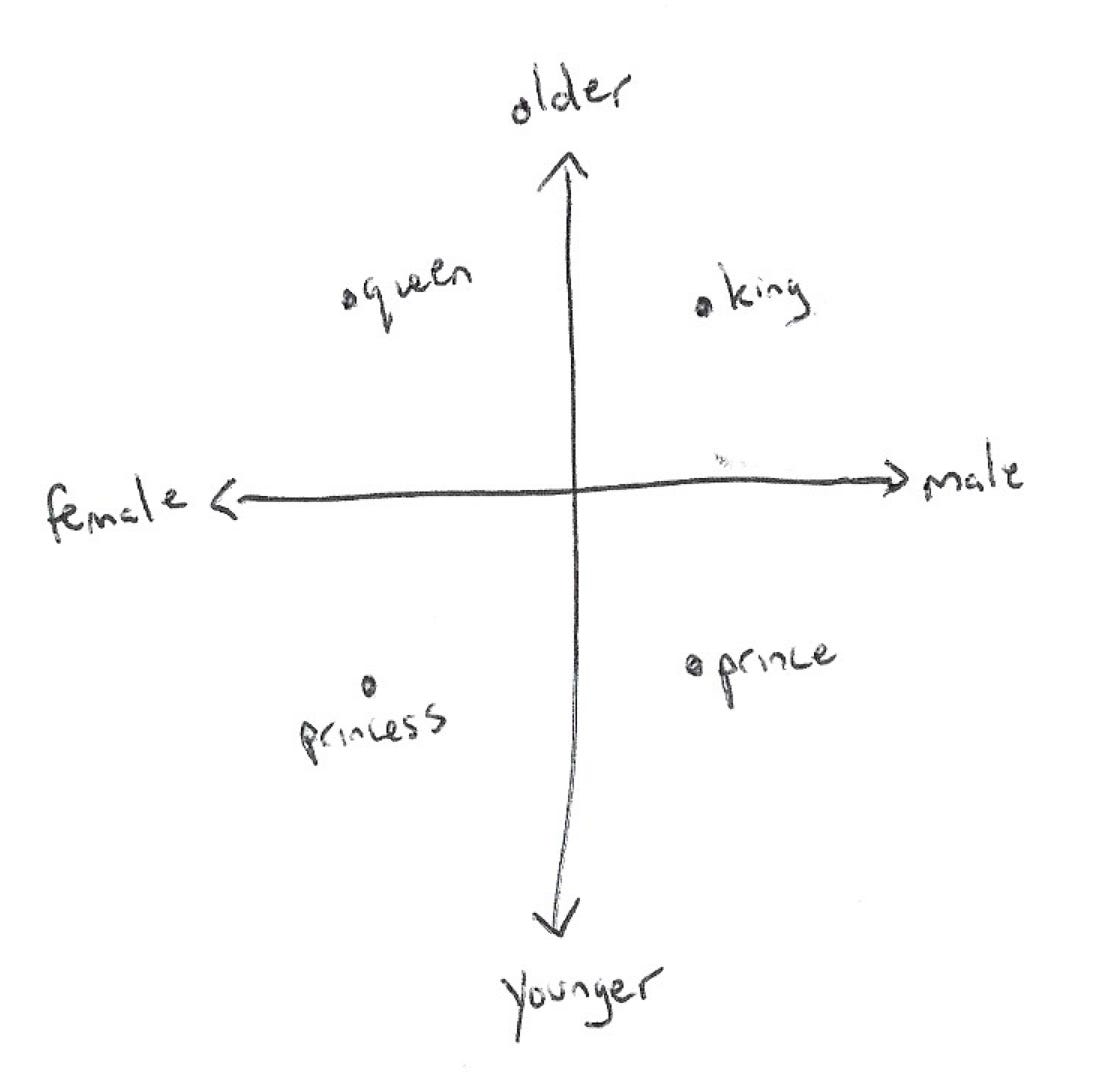
Whereas the letters of the words don’t carry much information about the meaning (except maybe that prince and princess have something in common), the graph actually represents the attributes of these words. This is something that a computer would be much more likely to understand.
The idea behind word vectors is that, if we were to create a graph with hundreds of dimensions instead of just two, we’d be able to capture the underlying meaning behind all the words in the English language.
For example, there might be a third dimension that represented “wealth” and all of these words would be high in that dimension, whereas “peasant” would be low.

Of course, with hundreds of dimensions, we don’t assign the meaning of each dimension. We don’t tell a computer that the y-axis means age and the x-axis means gender. Instead, we allow the AI model to figure out these dimensions for itself in a way that best teaches it the meaning.
This is surprisingly effective. In the Word2Vec paper, they famously show that once you’ve done this, you can add and subtract the vectors the model has learned, and the resulting vector really captures the “meaning” of the words:
Paris - France + Spain = Madrid
King - Man + Woman = Queen
Raptors - Toronto + Memphis = Grizzlies
Take a minute and think about how crazy that is. This kind of reasoning by analogy shows that the vectors are really capturing something about the deeper meaning of the word, which means we can start to use them to understand and create written language.
The Power of Vectors
Now that we have vectors representing words, pulling useful information out of text becomes much more manageable.
Let’s look at the simple code I shared above:
1) The model starts by downloading the GloVe embeddings. This is simply a text file with 100 dimensional vectors for the most common words in the English language.
2) Then it takes whatever text you input and cleans it, making everything lowercase, pulling out punctuation, and pulling out all the most common words that don’t carry meaning (like “the”).
3) With the clean text, it calculates a new vector for the full sentence by averaging the vectors of all the words in the sentence. This is a bit lazy and there are better ways to capture meaning, but it’s good for a simple illustration.
4) After doing that for each sentence, it compares all the resulting vectors and measures the cosine distance, looking for the vector that is most similar to the other vectors. In other words, it measures which sentence best represents all the other sentences.
Here’s another link to play around with it.
What’s cool about this is that it basically uses no AI. Once a set of word embeddings are figured out, the rest is just math to compare those. It’s about as simple as you can get, and it’s still surprisingly effective.
Stealing Fire
The real magic in the NLP space is happening at major companies, because training these models is ridiculously computationally expensive (GPT-3 has 175 billion parameters and took months and $12 million to train).
Here’s the thing: they almost always make these models freely available to download and customize as you see fit. This is incredibly powerful because the overall understanding of language is a skill that is needed for any NLP task you are trying to do, so these models have a huge head start on training something from scratch.
In other words, I can download a full model that a company like Google has spent months training and remove the “prediction end” of the model that customizes it for the task they trained it for. This leaves me with a neural network that has the deep understanding of language, but doesn’t know what task it’s supposed to do. Then it’s easy to add my own “head” to perform the task I need, and simply focus my training on just that part, rather than the full model.
This is called Transfer Learning, and it unlocks an unbelievable amount of power and leverage for individual developers.
I’ve been using Hugging Face for this and have been really impressed. They host versions of all the most common models, and make it easy to download them, use them, and customize them. I’ll share some of the more advanced stuff I’m building in the coming months, when it’s ready to be public.
What’s Possible?
This is definitely the area of AI that has my mind most exploding with ideas.
Everything we do is about interacting with language, and it seems like there are way more fun applications for NLP than for some of the other areas (like data analysis or image recognition) that I’ve studied previously.
There are so many things that become possible with the ability to work with text:
Question Answering: A Slack bot that learns everything in our company documentation and is able to answer questions that the team has and cut out all the searching.
Summarization: A Chrome extension to mouse over a link and get a pop up with a summary of the article, to avoid forming impressions from headlines.
Text Generation: Better email autocomplete trained on my own emails to understand my style and the things I most often communicate.
Text Classification: Monitoring and classifying social media mentions about our authors and books by positive or negative sentiment.
Beyond the fun practical things, there’s a deeper reason that language is exciting: Language is just a way of conveying meaning. To master language, you need to be able to capture that meaning, which isn’t so different from what our brains do every day.
It seems likely to me that the path to understanding (and creating) intelligence will most likely end up running through the tributaries of the work currently being done around language.
Until next month,
Zach